
Ran (Steven) Gong
Research Scientist at The Robotics and AI Institute
145 BroadwayCambridge, MA, 02142
nikepupu9 at gmail dot com
Research Scientist at The Robotics and AI Institute
145 Broadwaynikepupu9 at gmail dot com
I am a Research Scientist at The Robotics and AI Institute, where I focus on advancing the frontiers of artificial intelligence and robotics. I earned my Ph.D. from the University of California, Los Angeles, under the supervision of Professor Demetri Terzopoulos and Professor Song-chun Zhu. My research expertise spans the interdisciplinary domains of Robotics, Computer Vision, Computer Graphics, and Machine Learning, with a particular emphasis on developing intelligent systems that can understand and interact with the physical world.
During my doctoral studies, I collaborated extensively with Professor Gaurav Sukhatme (USC & Amazon Alexa AI), Dr. Siyuan Huang, and Dr. Tianmin Shu. I hold a Bachelor's degree in Computer Science and Engineering from UCLA, where I developed a strong foundation in both theoretical and applied aspects of computer science.
My research focuses on developing intelligent systems that can effectively learn and adapt in complex real-world environments. Key areas of interest include:

Ran Gong*,
Jiangyong Huang*,
Yizhou Zhao,
Haoran Geng,
Xiaofeng Gao,
Qingyang Wu,
Wensi Ai,
Ziheng Zhou,
Demetri Terzopoulos,
Song-Chun Zhu,
Baoxiong Jia,
Siyuan Huang
International Conference on Computer Vision (ICCV), 2023
Spotlight for LangRob @ CoRL 2022 Workshop

Xiaofeng Gao,
Ran Gong,
Tianmin Shu,
Xu Xie,
Shu Wang,
Song-Chun Zhu
ICML workshop on Reinforcement Learning for Real Life, 2019

@article{xu2026expertgen,
title={ExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors},
author={Xu, Zifan and Gong, Ran and Minniti, Maria Vittoria and Gundogdu, Ahmet Salih and Rosen, Eric and Sivakumar, Kausik and Yan, Riedana and Wang, Zixing and Deng, Di and Stone, Peter and Zhang, Xiaohan and Schmeckpeper, Karl},
journal={arXiv preprint arXiv:2603.15956},
year={2026}
}
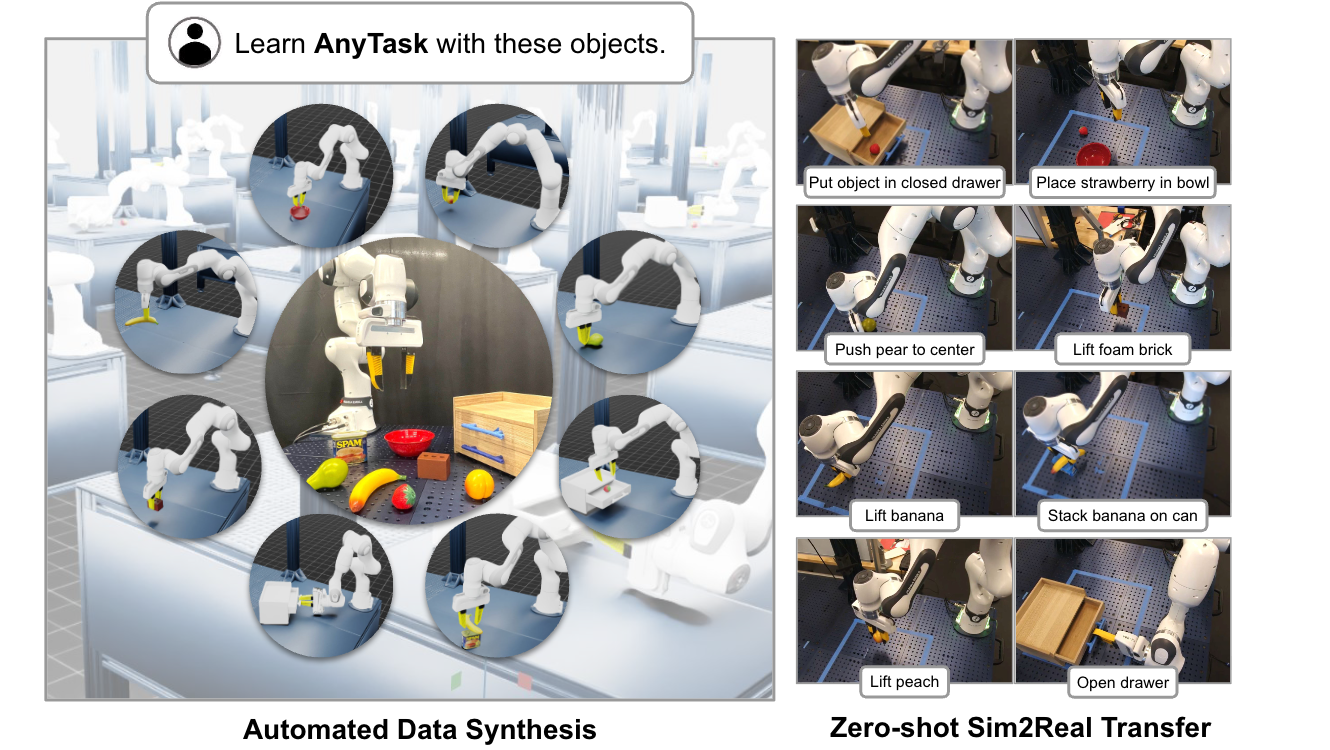
Ran Gong*, Xiaohan Zhang*, Jinghuan Shang*, Maria Vittoria
Minniti*,
Jigarkumar Patel, Valerio Pepe, Riedana Yan, Ahmet Gundogdu, Ivan Kapelyukh,
Ali Abbas,
Xiaoqiang Yan, Harsh Patel, Laura Herlant, Karl Schmeckpeper
arXiv preprint, 2025
@misc{gong2025anytask,
title={AnyTask: an Automated Task and Data Generation Framework for Advancing Sim-to-Real Policy Learning},
author={Gong, Ran and Zhang, Xiaohan and Shang, Jinghuan and Minniti, Maria Vittoria and Patel, Jigarkumar and Pepe, Valerio and Yan, Riedana and Gundogdu, Ahmet and Kapelyukh, Ivan and Abbas, Ali and Yan, Xiaoqiang and Patel, Harsh and Herlant, Laura and Schmeckpeper, Karl},
year={2025},
eprint={2512.17853},
archivePrefix={arXiv},
primaryClass={cs.RO}
}

@misc{shang2025sceniris,
title={Sceniris: A Fast Procedural Scene Generation Framework},
author={Shang, Jinghuan and Patel, Harsh and Gong, Ran and Schmeckpeper, Karl},
year={2025},
eprint={2512.16896},
archivePrefix={arXiv},
primaryClass={cs.RO}
}
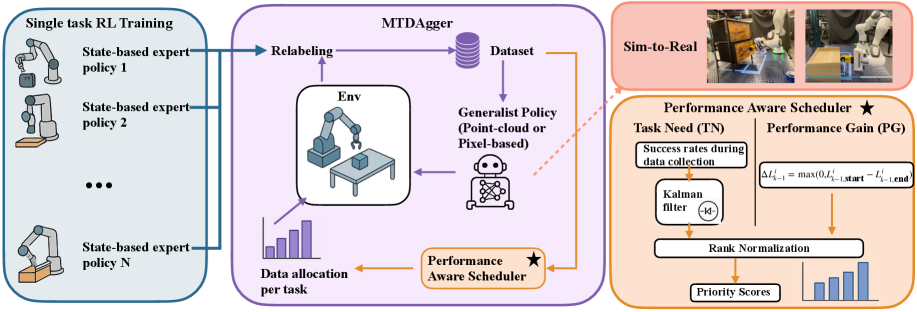
Haotian Fu, Ran Gong, Xiaohan Zhang, Maria Vittoria
Minniti, Jigarkumar Patel, Karl Schmeckpeper
arXiv preprint, 2025
@misc{fu2025dataefficient,
title={Data-Efficient Multitask DAgger},
author={Fu, Haotian and Gong, Ran and Zhang, Xiaohan and Minniti, Maria Vittoria and Patel, Jigarkumar and Schmeckpeper, Karl},
year={2025},
eprint={2509.25466},
archivePrefix={arXiv},
primaryClass={cs.LG}
}

Haoran Geng*, Feishi Wang*, Songlin Wei*, Yuyang Li*, Bangjun Wang*, Boshi
An*, Charlie Tianyue Cheng*,
Haozhe Lou, Peihao Li, Yen-Jen Wang, Yutong Liang, Dylan Goetting, Chaoyi
Xu, Haozhe Chen, Yuxi Qian,
Yiran Geng, Jiageng Mao, Weikang Wan, Mingtong Zhang, Jiangran Lyu, Siheng
Zhao, Jiazhao Zhang,
Jialiang Zhang, Chengyang Zhao, Haoran Lu, Yufei Ding, Ran
Gong, Yuran Wang, Yuxuan Kuang, Ruihai Wu,
Baoxiong Jia, Carlo Sferrazza, Hao Dong, Siyuan Huang, Koushil Sreenath, Yue
Wang, Jitendra Malik, Pieter Abbeel
Robotics: Science and Systems, 2025
@misc{geng2025roboverse,
title={RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning},
author={Haoran Geng and Feishi Wang and Songlin Wei and Yuyang Li and Bangjun Wang and Boshi An and Charlie Tianyue Cheng and Haozhe Lou and Peihao Li and Yen-Jen Wang and Yutong Liang and Dylan Goetting and Chaoyi Xu and Haozhe Chen and Yuxi Qian and Yiran Geng and Jiageng Mao and Weikang Wan and Mingtong Zhang and Jiangran Lyu and Siheng Zhao and Jiazhao Zhang and Jialiang Zhang and Chengyang Zhao and Haoran Lu and Yufei Ding and Ran Gong and Yuran Wang and Yuxuan Kuang and Ruihai Wu and Baoxiong Jia and Carlo Sferrazza and Hao Dong and Siyuan Huang and Koushil Sreenath and Yue Wang and Jitendra Malik and Pieter Abbeel},
year={2025},
primaryClass={cs.RO},
url={https://roboverse.wiki},
}

Wayne Wu*, Honglin He*, Chaoyuan Zhang, Jack He, Seth Z. Zhao, Ran
Gong, Quanyi Li, and Bolei Zhou
IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)
Highlight, 2025
@inproceedings{wu2025urbansim,
title={Towards Autonomous Micromobility through Scalable Urban Simulation},
author={Wu, Wayne and He, Honglin and Zhang, Chaoyuan and He, Jack and Zhao, Seth Z. and Gong, Ran and Li, Quanyi and Zhou, Bolei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}
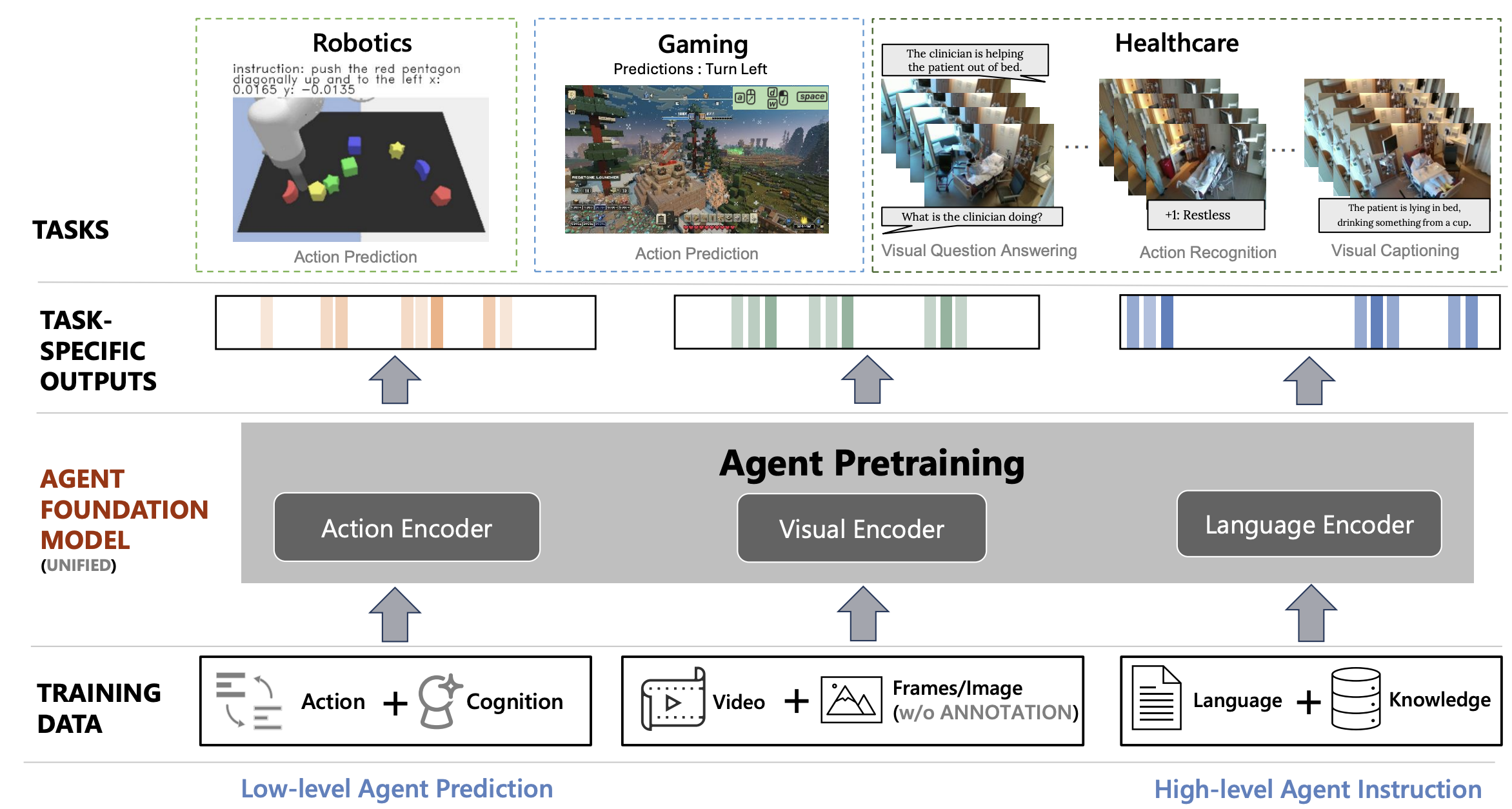
Zane Durante*,
Ran Gong*,
Bidipta Sarkar*,
Naoki Wake,
Rohan Taori,
Paul Tang,
Shrinidhi Lakshmikanth,
Kevin Schulman,
Arnold Milstein,
Hoi Vo,
Ehsan Adeli,
Demetri Terzopoulos,
Li Fei-Fei,
Jianfeng Gao
IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)
Workshops, 2025
@InProceedings{Durante_2025_CVPR,
author = {Durante, Zane and Gong, Ran and Sarkar, Bidipta and Wake, Naoki and Taori, Rohan and Tang, Paul and Lakshmikanth, Shrinidhi and Schulman, Kevin and Milstein, Arnold and Vo, Hoi and Adeli, Ehsan and Terzopoulos, Demetri and Fei-Fei, Li and Gao, Jianfeng},
title = {An Interactive Agent Foundation Model},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops},
month = {June},
year = {2025},
pages = {3652-3662}
}
Ran Gong*,
Jiangyong Huang*,
Yizhou Zhao,
Haoran Geng,
Xiaofeng Gao,
Qingyang Wu,
Wensi Ai,
Ziheng Zhou,
Demetri Terzopoulos,
Song-Chun Zhu,
Baoxiong Jia,
Siyuan Huang
International Conference on Computer Vision (ICCV), 2023
Spotlight for LangRob @ CoRL 2022 Workshop
@article{gong2023arnold,
title={ARNOLD: A Benchmark for Language-Grounded Task Learning With Continuous States in Realistic 3D Scenes},
author={Gong, Ran and Huang, Jiangyong and Zhao, Yizhou and Geng, Haoran and Gao, Xiaofeng and Wu, Qingyang and Ai, Wensi and Zhou, Ziheng and Terzopoulos, Demetri and Zhu, Song-Chun and others},
journal={arXiv preprint arXiv:2304.04321},
year={2023}
}

Ran Gong,
Xiaofeng Gao,
Qiaozi Gao,
Suhaila Shakiah,
Govind Thattai,
Gaurav S. Sukhatme
IEEE Robotics and Automation Letters (RA-L), 2023
@article{gong2023lemma,
title={LEMMA: Learning Language-Conditioned Multi-Robot Manipulation},
author={Gong, Ran and Gao, Xiaofeng and Gao, Qiaozi and Shakiah, Suhaila and Thattai, Govind and Sukhatme, Gaurav S},
journal={arXiv preprint arXiv:2308.00937},
year={2023}
}
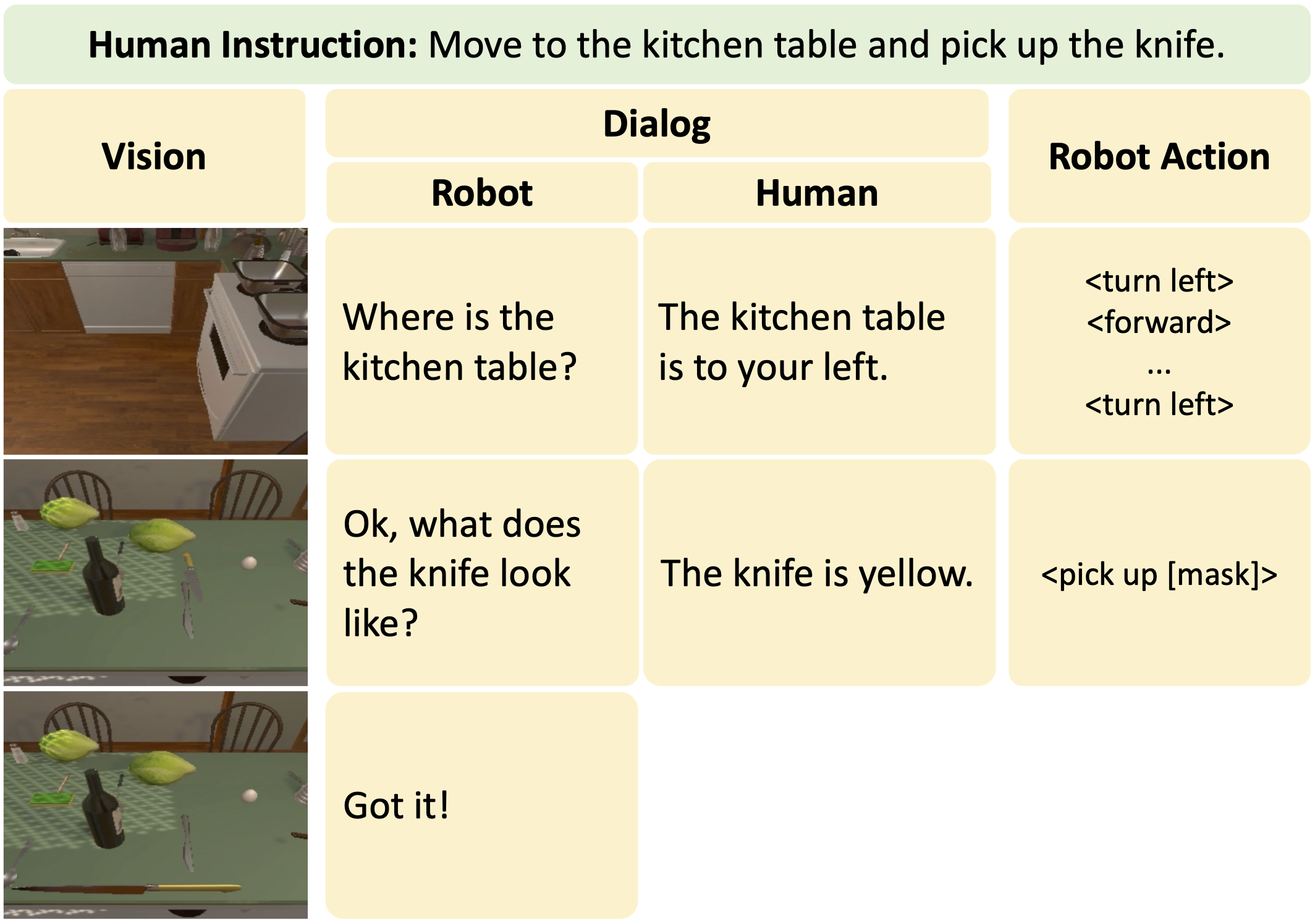
@article{gao2022dialfred,
title={DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following},
author={Gao, Xiaofeng and Gao, Qiaozi and Gong, Ran and Lin, Kaixiang and Thattai, Govind and Sukhatme, Gaurav S.},
journal={IEEE Robotics and Automation Letters},
year={2022},
volume={7},
pages={10049-10056},
doi={10.1109/LRA.2022.3193254}
}
Xiaofeng Gao,
Ran Gong,
Tianmin Shu,
Xu Xie,
Shu Wang,
Song-Chun Zhu
ICML workshop on Reinforcement Learning for Real Life, 2019
@article{gao2019vrkitchen,
title={Vrkitchen: an interactive 3d virtual environment for task-oriented learning},
author={Gao, Xiaofeng and Gong, Ran and Shu, Tianmin and Xie, Xu and Wang, Shu and Zhu, Song-Chun},
journal={arXiv preprint arXiv:1903.05757},
year={2019}
}

@article{long2024teamcraft,
title={TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft},
author={Long, Qian and Li, Zhi and Gong, Ran and Wu, Ying Nian and Terzopoulos, Demetri and Gao, Xiaofeng},
journal={arXiv preprint arXiv:2412.05255},
year={2024}
}
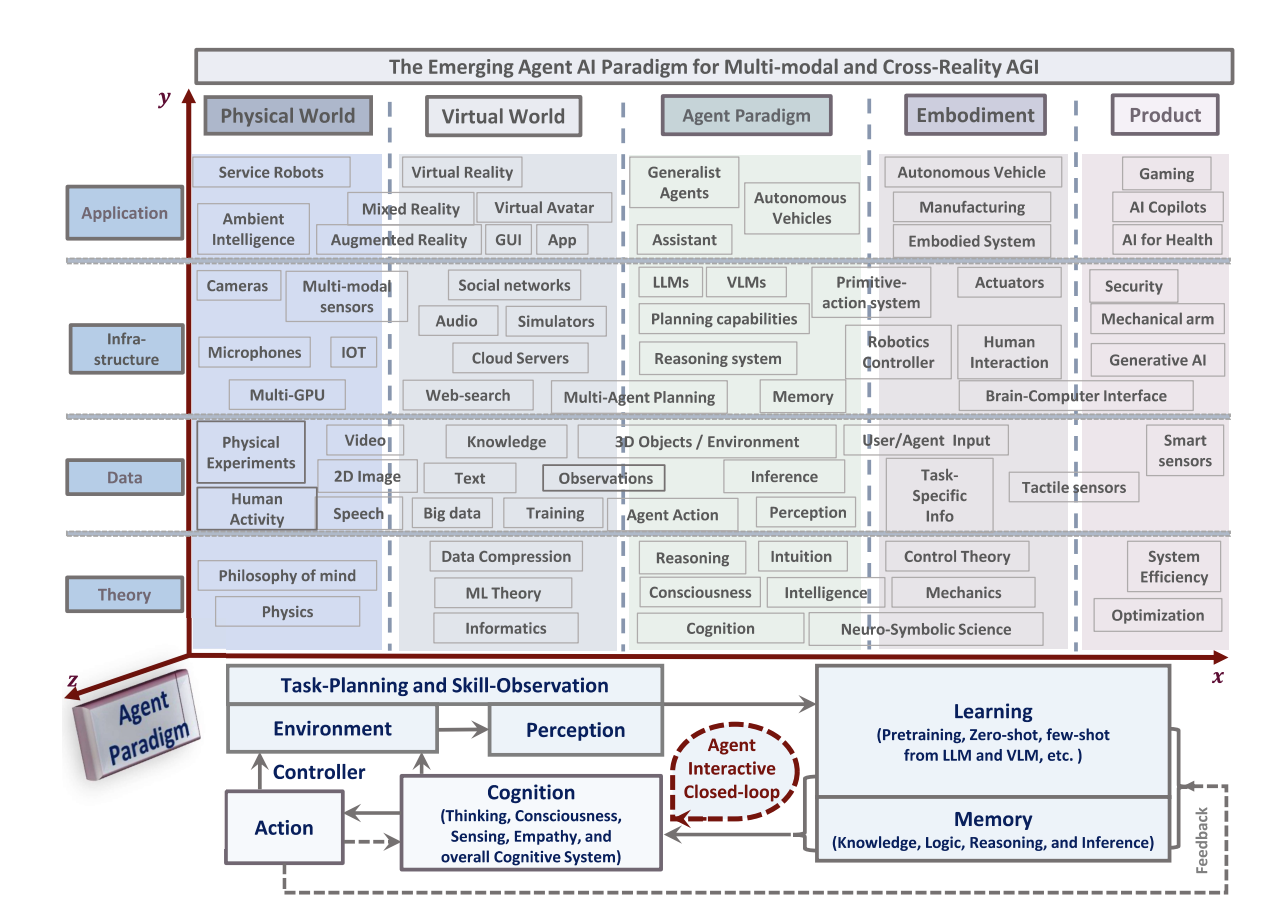
Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung
Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin
Choi, Katsushi Ikeuchi, Hoi Vo, Li Fei-Fei, Jianfeng Gao
arXiv preprint, 2024
@article{durante2024agent,
title={Agent AI: Surveying the Horizons of Multimodal Interaction},
author={Durante, Zane and Huang, Qiuyuan and Wake, Naoki and Gong, Ran and Park, Jae Sung and Sarkar, Bidipta and Taori, Rohan and Noda, Yusuke and Terzopoulos, Demetri and Choi, Yejin and Ikeuchi, Katsushi and Vo, Hoi and Fei-Fei, Li and Gao, Jianfeng},
journal={arXiv preprint arXiv:2401.03568},
year={2024}
}
@article{gong2023mindagent,
title={MindAgent: Emergent Gaming Interaction},
author={Gong, Ran and Huang, Qiuyuan and Ma, Xiaojian and Vo, Hoi and Durante, Zane and Noda, Yusuke and Zheng, Zilong and Terzopoulos, Demetri and Fei-Fei, Li and others},
journal={arXiv preprint arXiv:2309.09971},
year={2023}
}
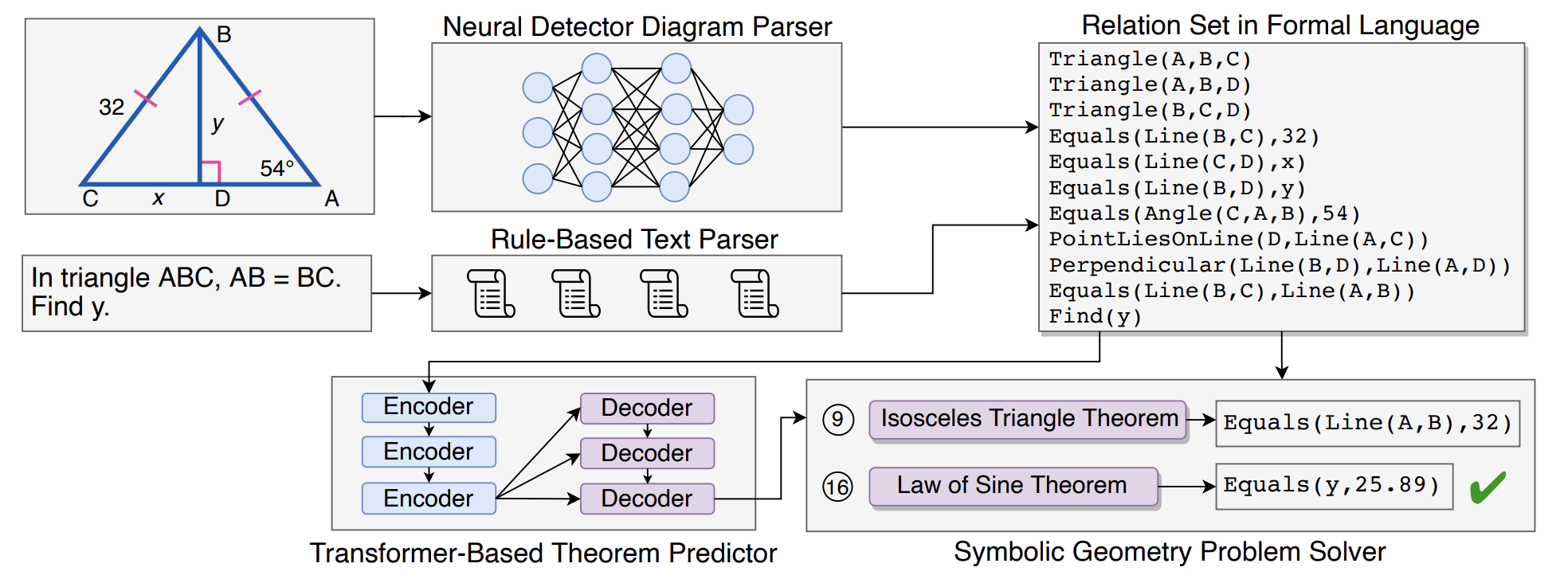
@inproceedings{lu2021inter,
title={Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning},
author={Lu, Pan and Gong, Ran and Jiang, Shibiao and Qiu, Liang and Huang, Siyuan and Liang, Xiaodan and Zhu, Song-Chun},
booktitle={The 59th Annual Meeting of the Association for Computational Linguistics (ACL)},
year={2021}
}
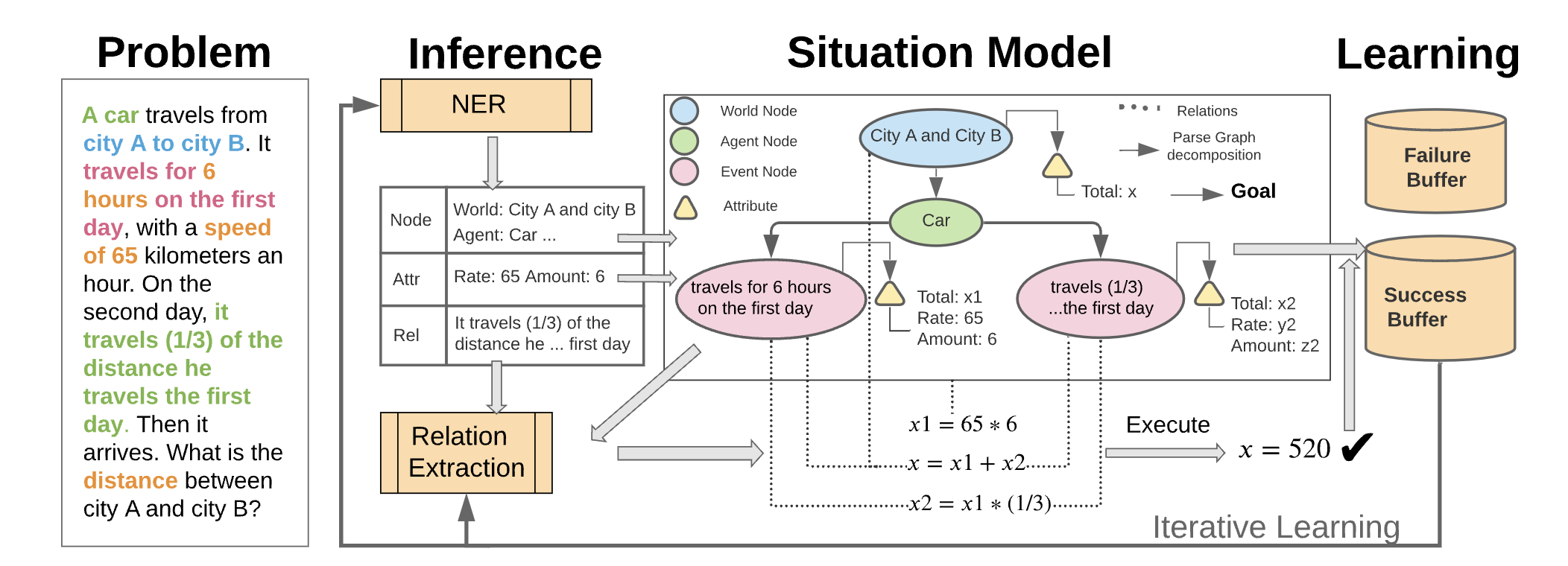
@inproceedings{hong2021smart,
title={SMART: A Situation Model for Algebra Story Problems via Attributed Grammar},
author={Hong, Yining and Li, Qing and Gong, Ran and Ciao, Daniel and Huang, Siyuan and Zhu, Song-Chun.},
booktitle={The Thirty-Fifth AAAI Conference on Artificial Intelligence, {AAAI-21}},
year={2021}
}
Xiaofeng Gao*,
Ran Gong*,
Yizhou Zhao,
Shu Wang,
Tianmin Shu,
Song-Chun Zhu
IEEE International Conference on Robot & Human Interactive Communication
(RO-MAN), 2020
@inproceedings{gao2020joint,
title={Joint Mind Modeling for Explanation Generation in Complex Human-Robot Collaborative Tasks},
author={Gao, Xiaofeng and Gong, Ran and Zhao, Yizhou and Wang, Shu and Shu, Tianmin and Zhu, Song-Chun},
booktitle={2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)},
pages={1119--1126},
year={2020},
organization={IEEE}
}

Zhixiong Nan,
Tianmin Shu,
Ran Gong,
Shu Wang,
Ping Wei,
Song-Chun Zhu,
Nanning Zheng
Pattern Recognition 2020
@article{nan2020learning,
title={Learning to infer human attention in daily activities},
author={Nan, Zhixiong and Shu, Tianmin and Gong, Ran and Wang, Shu and Wei, Ping and Zhu, Song-Chun and Zheng, Nanning},
journal={Pattern Recognition},
volume={103},
pages={107314},
year={2020},
publisher={Elsevier}
}